Déjà il faut télécharger le "logiciel" sur Github qui peut lancer le "modèle" ici le RealVisXL V5.0 qui était décrit dans la vidéo.
1- le logiciel
C'est par là et ça s'appelle comfyanonymous/ComfyUI, à savoir c'est compressé en 7zip et ça fait 1.51 GB (plus de 2Go décompressé).
Déjà ce qui est bien, c'est qu'il intègre tout ce qu'il faut, les bonnes versions du logiciel Python, etc ... le tout dans une archive à décompresser. Mais ce n'est pas fini.
Première remarque: poser ça sur un disque qui a plus de 10 Go de place !!!
Donc allez sur https://github.com/comfyanonymous/ComfyUI/releases, téléchargez la dernière release, moi c'était ComfyUI_windows_portable_nvidia.7z
Ensuite donc le décompresser avec votre logiciel favori, perso 7zip.
On va dire que je l'ai décompressé, chez moi dans mon
D:\IA\ComfyUI_windows_portable
Accessoirement lire le README ;)
RTFM !
2- le modèle
Mais ce n'est pas tout, il faut ensuite télécharger le modèle. En effet ComfyU n'en contient pas ... encore.
Le modèle est donc là: RealVisXL V5.0 @civitai.com => cliquer sur download pour 6.46Go à cette heure.
Étape suivante, bouger ce modèle (nommé realvisxlV50_v50LightningBakedvae.safetensors) dans
D:\IA\ComfyUI_windows_portable\ComfyUI\models\checkpoints
3- le lancer
Il faut ouvrir une console (un DOS quoi) et aller dans le répertoire D:\IA\ComfyUI_windows_portable
Là, vu que j'ai une carte NVIDIA, je peux lancer la commande
run_nvidia_gpu.bat
qui va s'occuper de lancer le serveur en local et vous ouvrir une page Web locale dans votre browser préféré, au bout de quelques secondes.
Sinon si vous n'avez pas de carte NVIDIA c'est
run_cpu.bat
(pas essayé !)
3- le configurer
Il faut choisir le modèle, au moins une fois (RealVisXL V5.0) là: SI C'EST VIDE ! en cliquant sur la flèche.
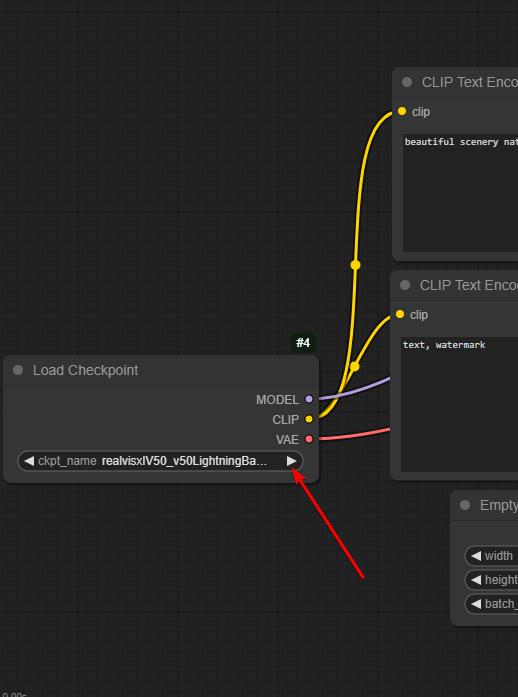
Sans lui rien ne marchera.
Pour le premier essai, laissez les prompts comme ils sont.
Moi j'ai modifié les paramètres comme cela (je n'y connais rien, je débute, j'ai essayé de faire au plus proche de ce qui était dit dans la vidéo)
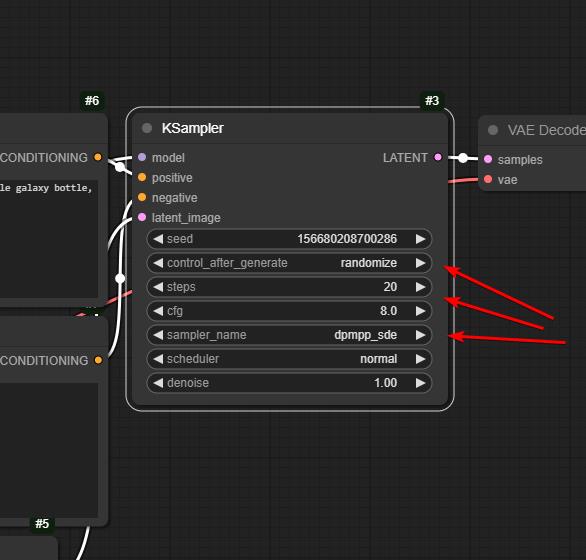
En gros control à "randomize"
Steps à 20 (ou plus)
Sampler à "dpmpp_sde"
Vous pourrez jouer avec plus tard pour voir des différences.
On peut aussi modifier la taille de l'image générée dans "Empty latent image". Le batch_size dedans, c'est le nombre d'image en une fois que vous voulez générer. Elles s'afficheront alors Dans "Save Image" 1/X
4- lancer son premier build
Ça se passe là dedans
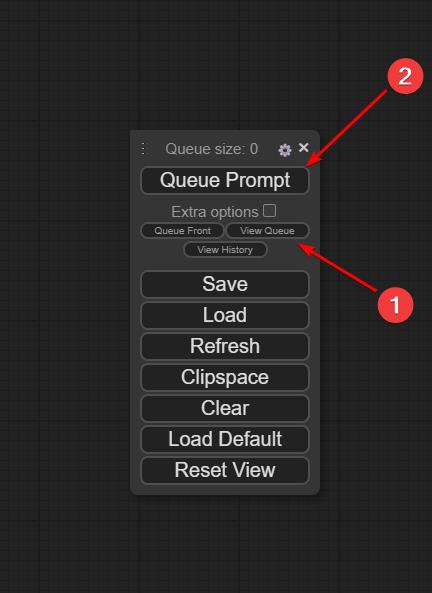
- afficher la queue de travail
- lancer le "build" de l'image (à partir des prompts)
- la partie du scénario qui est lancé qui est en court d’exécution est alors entourée en vert.
Cf ci dessous, la première fois le "Load Checkpoint" va prendre du temps !
Et donc rester entouré de vert "longtemps". Ensuite ce sera au tour du "KSampler" mais lui a une barre de progression. - Enfin, l'image apparaitra dans le "Save image". En faisant un "click-droit" sur l'image vous pouvez faire "open", "save", ...
- Une image NON SAUVÉE est perdue ! Une génération suivante va l'écraser.
Notes importantes, parce que ça prend du TEMPS. Et que ce n'est pas parce que RIEN n'avance que ça ne marche pas (je me suis fait avoir)
- La toute première fois que vous lancez le modèle via le promt, après avoir lancé le
run_nvidia_gpu.batchez moi ça a pris PLUS DE 5mn pour générer l'image. Je suppose que c'est une phase normale d'initialisation/décompression du modèle ... quelque part. Après c'était 1 minute par image. - Ensuite chaque fois que vous modifiez un prompt, la génération prendra aussi un peu plus de temps (que la minute référence chez moi (qui sera différente chez vous en fonction de la puissance de votre machine))
Bref, laissez le programme tourner tant que vous voulez générer des images, pour éviter ces minutes supplémentaires lors de la première image après avoir lancé ComfyUI.
De base dans le prompt du haut, il y avait chez moi:
beautiful scenery nature glass bottle landscape, , purple galaxy bottle,
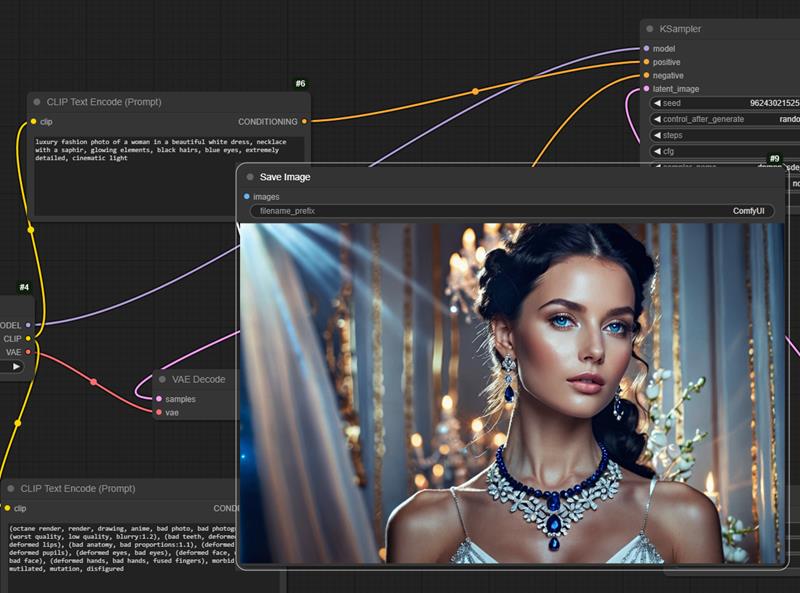
C'est dans celui là qu'il faut décrire ce qu'on "veut". pour mon image exemple d'en haut j'avais mis:
luxury fashion photo of a woman in a beautiful white dress, necklace with a saphir, glowing elements, black hairs, blue eyes, extremely detailed, cinematic light
Mais écrire un prompt est tout un art que je ne maitrise pas (encore).
Je vous conseille de mettre dans le prompt du bas, ce qu'ils appellent le "negative prompt", c'est à dire TOUT CE QU'ON NE VEUT PAS comme problèmes dans les images générées. Mais ça peut aussi jouer si vous voulez des images "pas normales", cf mon test R2D2 plus bas.
Voilà celui que j'ai pris: trouvé dans la vidéo de présentation de hier.
(octane render, render, drawing, anime, bad photo, bad photography:1.3), (worst quality, low quality, blurry:1.2), (bad teeth, deformed teeth, deformed lips), (bad anatomy, bad proportions:1.1), (deformed iris, deformed pupils), (deformed eyes, bad eyes), (deformed face, ugly face, bad face), (deformed hands, bad hands, fused fingers), morbid, mutilated, mutation, disfigured
Voilà, en théorie vous pouvez jouer avec. A chaque fois que vous cliquez sur "Queue prompt", une image va se créer.
ENJOY !
PS: par exemple pour ce prompt
photo of R2D2 sticking out a very big tongue, extremely detailed, cinematic light
J'ai du enlever le "negative prompt" et y remettre
text, watermark
pour bien avoir une image avec une langue alors que le l'avais explicitement demandée "photo of R2D2 sticking out a very big tongue" ;)
